Da più di un mese volevo scrivere due righe introduttive su come si crea un bot utilizzando il framework Microsoft, e finalmente agli sgoccioli delle vacanze natalizie sono riuscito a raccogliere quel poco di voglia e tempo necessari.

Quella che segue è una rielaborazione – spero semplificata – di ciò che Giulio Santoli e Vito Flavio Lorusso ci hanno mostrato al Bot Revolution Lab dell’ultimo Codemotion di Milano.
Il repository Github: github.com/vflorusso/botrevolution/
Le slides: www.slideshare.net/gjuljo/bot-revolution-lab-at-codemotion-milan-2016
Alternative al framework Microsoft
Chiaramente questa della Microsoft è solo una delle tante opzioni per creare un bot e collegarlo ai canali che ci interessano, e cercando un po’ se ne trovano molte che possono essere migliori per certi aspetti e peggiori per altri.
La differenza credo la facciano il motore di comprensione del linguaggio (più o meno imprescindibile), il costo, il linguaggio di sviluppo, la compatibilità con i principali programmi di messaggistica, la modularità di tutte le varie componenti e la facilità di integrazione con api di terze parti. Tra le altre cose al Codemotion la Cisco (uno degli sponsor) ha mostrato Tropo, delle api con cui – pagando un tanto al chilo – si possono aggiungere funzionalità ai propri bot come la possibilità di effettuare chiamate con voce registrata o text-to-speech, di interpretare la voce di chi risponde utilizzando lo speech-to-text, di inviare sms… in sostanza è un mondo in grande evoluzione e con moltissimi contendenti.
Starli a descrivere a grandi linee sarebbe inutile, un po’ perché non li conosco e un po’ perché andrei off-topic, ritorno quindi sul framework Microsoft ipotizzando che sia “il migliore” in circolazione.
Panoramica sugli strumenti utilizzati
Il laboratorio del Codemotion è durato un’ora e mezza, e in questo lasso di tempo siamo partiti da un ambiente più o meno già configurato per lo sviluppo arrivando a collegare vari bot – pubblicati sulla propria macchina – a Skype, Telegram e Slack.
Si sono utilizzati vari strumenti, che conviene introdurre brevemente perché per lo più possono tornare utili a prescindere dai bot.
ngrok
Si pronuncia “en grok” ed è un sistema di tunneling – http ma non solo – utilissimo quando si vuole sviluppare qualcosa localmente rendendolo accessibile temporaneamente dal web ma senza aprire porte su eventuali firewall.
ngrok.com
Bot Builder SDK
L’sdk con cui scrivere il bot, in C# o NodeJS. Sul repository Github ci sono moltissimi esempi in entrambi i linguaggi.
github.com/Microsoft/BotBuilder
Bot Framework Emulator
Un emulatore desktop multipiattaforma con varie funzionalità utili per testare il proprio bot, sia in locale che dopo averlo pubblicato.
docs.botframework.com/en-us/tools/bot-framework-emulator
LUIS
“Language Understanding Intelligent Service”, ovvero le API Microsoft per la comprensione del linguaggio, utilizzabili in ogni genere di applicazione.
www.luis.ai
Visual Studio Code
Si può utilizzare l’ide o l’editor che si preferisce, ma Visual Studio Code può essere una soluzione ideale sia che si decida di scrivere in Javascript che in C#.
code.visualstudio.com
Preparazione dell’ambiente di sviluppo per l’sdk NodeJS
Per iniziare a sviluppare il proprio bot in locale:
- procurarsi una versione aggiornata di NodeJS
Nota: a me la versione 7 diede qualche problema e finii per usare la 6.9.x.
- installare il bot framework emulator
- scaricare l’eseguibile di ngrok e copiarlo dove rimane più comodo
- inizializzare un progetto Node nella cartella di lavoro:
npm init
- installare le dipendenze del progetto:
npm install botbuilder restify dotenv-extended --save
Se si vuole chiudere il cerchio andando a pubblicare il proprio bot collegandolo a un sistema di messaggistica:
- pubblicare il proprio bot da qualche parte sul cloud (temporaneamente si può usare la propria macchina e ngrok)
- farsi un account Microsoft su login.live.com
- crearsi un account sui servizi di messaggistica che ci interessano (Slack, Skype, Telegram, …)
Bot Sanculotto – Salut world
L’obiettivo sarebbe stato quello di sviluppare un bot capace di dire all’utente la data o l’ora usando il calendario rivoluzionario/repubblicano francese o l’orologio decimale, con un minimo di capacità di interpretazione della domanda. In corso d’opera però mi sono reso conto che per sviluppare i pezzi che mi mancano ci avrei messo troppo, e che forse in questa prima parte era meglio fare una panoramica del framework, quindi per non fargli dire “Hello world” al momento Sanculotto risponde “Salut” a tutti.
var builder = require('botbuilder');
var restify = require('restify');
var connector = new builder.ChatConnector();
var bot = new builder.UniversalBot(connector);
bot.dialog('/', [
function(session) {
session.send('Salut');
},
]);
/* LISTEN IN THE CHAT CONNECTOR */
var server = restify.createServer();
server.listen(process.env.port || process.env.PORT || 3978, function () {
console.log('%s listening to %s', server.name, server.url);
});
server.post('/api/messages', connector.listen());
Questo codice risponde “Salut” a qualunque tipo di messaggio, il resto se mai vedrà la luce lo metterò su Github e cercherò di sfruttarlo per una secondo articoletto.
Test in locale con il framework emulator
Conviene partire dal caso più semplice, sufficiente per sviluppare l’eventuale logica del bot – qui assente – senza stare a scomodare servizi in cloud e sistemi di messaggistica vari.

Configurazione dell’emulatore per rendergli accessibile ngrok

Avvio del bot con “node index.js”, per comodità possiamo usare il terminale integrato in Visual Studio Code

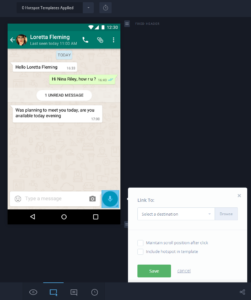
Test con l’emulatore dopo aver specificato l’endpoint locale
Collegamento con account Microsoft e test su Skype
Lo script è come quello di prima con la differenza che questa volta per creare il chat connector dobbiamo usare delle credenziali Microsoft.
Per far questo creiamo nella stessa directory dello script un file .env contenente le credenziali di cui sopra, e nello script le utilizziamo dopo aver caricato il modulo dotenv-extended. Le inseriremo nel file subito dopo aver registrato il bot sul portale della Microsoft.
require('dotenv-extended').load();
// ...
var connector = new builder.ChatConnector({appId: process.env.MICROSOFT_APP_ID, appPassword: process.env.MICROSOFT_APP_PASSWORD});
// ...
MICROSOFT_APP_ID=
MICROSOFT_APP_PASSWORD=

Registrazione del bot sul portale della Microsoft

Lancio di ngrok con ./ngrok http 3978
Un piccolo chiarimento sull’ordine temporale delle operazioni è d’obbligo.
Il portale Microsoft vuole sapere l’endpoint di pubblicazione del nostro bot, che in questo caso è ancora sulla nostra macchina. Sappiamo che la porta è la 3978 perché abbiamo messo in ascolto il nostro server node su quella porta, quindi avviamo ngrok per fare il tunneling http in quella posizione, e copiamo l’indirizzo di forwarding in https sul portale aggiungendo /api/messages perché è quella la nostra root.
A questo punto possiamo generare le credenziali (app-id e password) dal portale e copiarle nel file .env; se tutto è stato configurato correttamente dovrebbe ora essere sufficiente avviare l’applicazione per poter dialogare con il bot dall’interfaccia web del portale Microsoft. Inserendo l’endpoint completo e le credenziali generate sopra sull’emulatore possiamo testare l’applicazione anche con quest’ultimo.

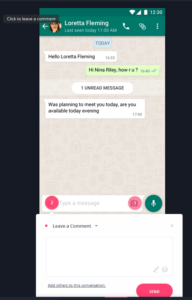
Test dall’interfaccia web del portale Microsoft
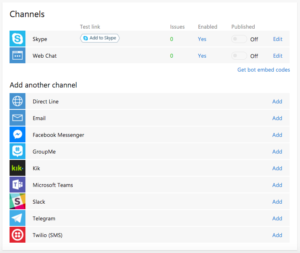
Canali disponibili
Una volta registrato sul portale possiamo collegare il nostro bot su tutti i canali che si vuole, la lista è lunga. Naturalmente è necessario avere un account sul sistema di messaggistica che ci interessa, e la procedura di registrazione è diversa per ciascun canale. Quella di Skype chiaramente è la più semplice essendo tutta roba Microsoft, un paio di click e possiamo usarlo per comunicare con Sanculotto.

Test tramite Skype
Nota: ricordiamoci che per la Microsoft l’endpoint del bot è (ancora) l’url generato da ngrok, ed è dinamico. Ogni volta che arrestiamo e riavviamo quest’ultimo dobbiamo quindi andare a sostituire l’url sul portale, almeno finché non pubblichiamo il codice del bot da qualche parte in cloud.
Per concludere
Questa è chiaramente solo un’introduzione al framework, che al primo approccio potrebbe risultare un po’ ostile anche perché abbastanza modulare.
Su Github ci sono molti esempi di bot più o meno complessi, alcuni anche basati su Luis – le api di comprensione del linguaggio – che qui non ho affrontato minimamente un po’ perché meritano un articolo a parte e un po’ perché le ho viste solo cinque minuti più di un mese fa.
Il prossimo passo dovrebbe essere quello di dare a Sanculotto qualche capacità in più, perché al momento il suo rispondere sempre “Salut” a qualunque messaggio lo rende abbastanza poco utile. Conto di farlo nelle prossime due o tre settimane.
A grandi linee penso di pubblicare le api di calcolo del calendario in ASP.NET su Azure perché ho già del codice in c#, e il bot in Javascript sempre su Azure all’interno dello stesso service plan così da minimizzare il traffico tra i due; per l’interpretazione delle richieste in linguaggio naturale c’è Luis, che chiaramente dovrà essere istruito a dovere. In queste ultime quattro righe credo di aver riassunto le potenzialità di questo framework, la cui forza principale è l’enorme ecosistema Microsoft su cui può (ma non necessariamente deve) far affidamento.